2025
MAPLE: Multi-Agent Adaptive Planning with Long-Term Memory for Table Reasoning
Ye Bai, Minghan Wang, Thuy-Trang Vu
The 23rd Annual Workshop of the Australasian Language Technology Association (ALTA 2025) 2025
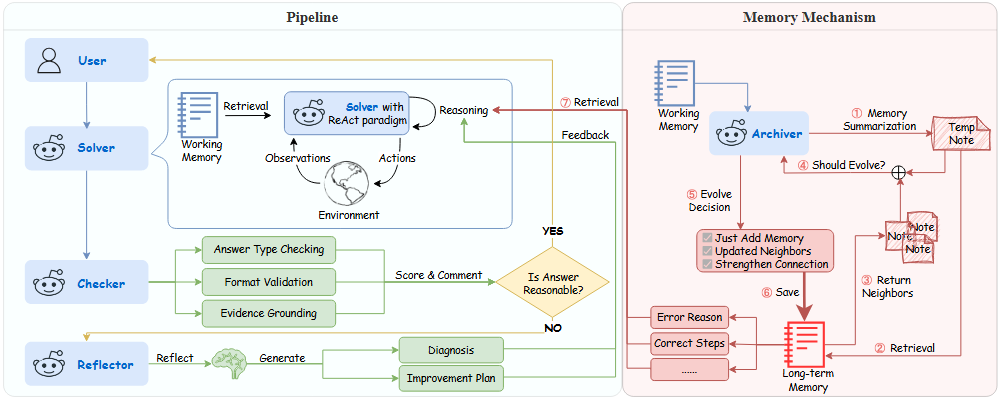
Table-based question answering requires complex reasoning capabilities that current LLMs struggle to achieve with single-pass inference. Existing approaches, such as Chain-of-Thought reasoning and question decomposition, lack error detection mechanisms and discard problem-solving experiences, contrasting sharply with how humans tackle such problems. In this paper, we propose MAPLE (Multi-agent Adaptive Planning with Long-term mEmory), a novel framework that mimics human problem-solving through specialized cognitive agents working in a feedback-driven loop. MAPLE integrates 4 key components: (1) a Solver using the ReAct paradigm for reasoning, (2) a Checker for answer verification, (3) a Reflector for error diagnosis and strategy correction, and (4) an Archiver managing long-term memory for experience reuse and evolution. Experiments on WiKiTQ and TabFact demonstrate significant improvements over existing methods, achieving state-of-the-art performance across multiple LLM backbones.
MAPLE: Multi-Agent Adaptive Planning with Long-Term Memory for Table Reasoning
Ye Bai, Minghan Wang, Thuy-Trang Vu
The 23rd Annual Workshop of the Australasian Language Technology Association (ALTA 2025) 2025
Table-based question answering requires complex reasoning capabilities that current LLMs struggle to achieve with single-pass inference. Existing approaches, such as Chain-of-Thought reasoning and question decomposition, lack error detection mechanisms and discard problem-solving experiences, contrasting sharply with how humans tackle such problems. In this paper, we propose MAPLE (Multi-agent Adaptive Planning with Long-term mEmory), a novel framework that mimics human problem-solving through specialized cognitive agents working in a feedback-driven loop. MAPLE integrates 4 key components: (1) a Solver using the ReAct paradigm for reasoning, (2) a Checker for answer verification, (3) a Reflector for error diagnosis and strategy correction, and (4) an Archiver managing long-term memory for experience reuse and evolution. Experiments on WiKiTQ and TabFact demonstrate significant improvements over existing methods, achieving state-of-the-art performance across multiple LLM backbones.
Discrete Minds in a Continuous World: Do Language Models Know Time Passes?
Minghan Wang, Ye Bai, Thuy-Trang Vu, Ehsan Shareghi, Gholamreza Haffari
Conference on Empirical Methods in Natural Language Processing (EMNLP) 2025
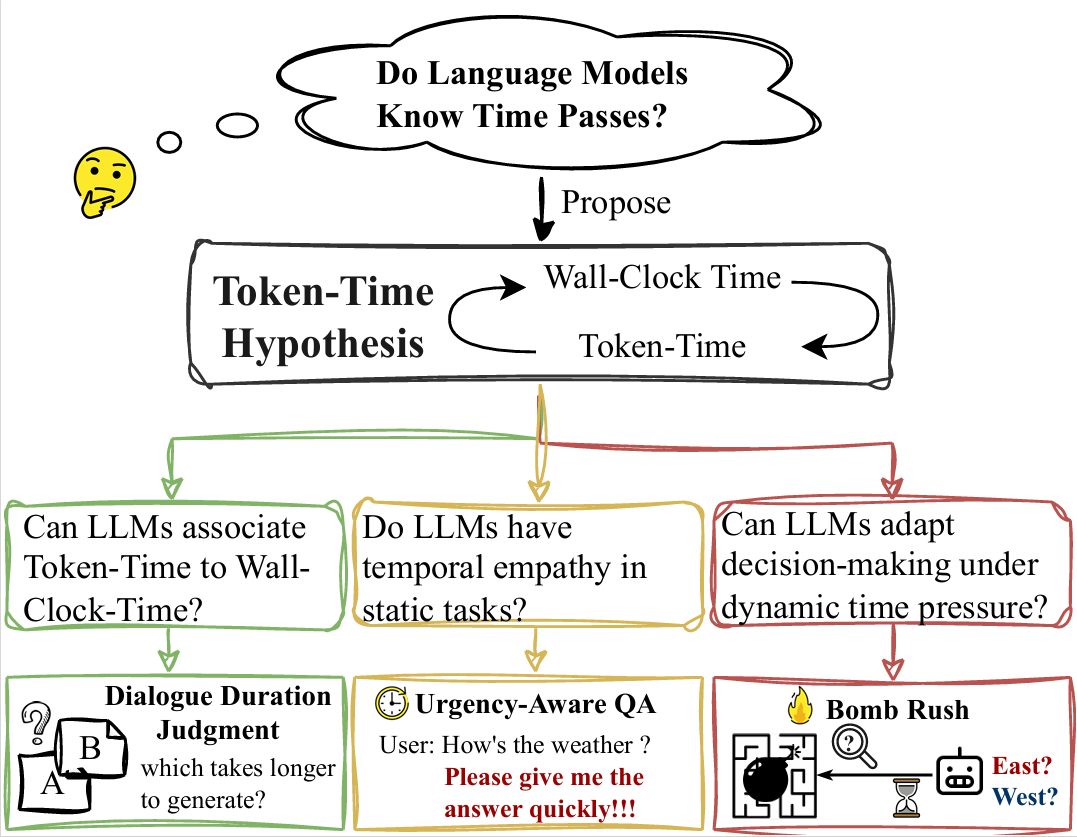
While Large Language Models (LLMs) excel at temporal reasoning tasks like event ordering and duration estimation, their ability to perceive the actual passage of time remains unexplored. We investigate whether LLMs perceive the passage of time and adapt their decision-making accordingly through three complementary experiments. First, we introduce the Token-Time Hypothesis, positing that LLMs can map discrete token counts to continuous wall-clock time, and validate this through a dialogue duration judgment task. Second, we demonstrate that LLMs could use this awareness to adapt their response length while maintaining accuracy when users express urgency in question answering tasks. Finally, we develop BombRush, an interactive navigation challenge that examines how LLMs modify behavior under progressive time pressure in dynamic environments. Our findings indicate that LLMs possess certain awareness of time passage, enabling them to bridge discrete linguistic tokens and continuous physical time, though this capability varies with model size and reasoning abilities. This work establishes a theoretical foundation for enhancing temporal awareness in LLMs for time-sensitive applications.
Discrete Minds in a Continuous World: Do Language Models Know Time Passes?
Minghan Wang, Ye Bai, Thuy-Trang Vu, Ehsan Shareghi, Gholamreza Haffari
Conference on Empirical Methods in Natural Language Processing (EMNLP) 2025
While Large Language Models (LLMs) excel at temporal reasoning tasks like event ordering and duration estimation, their ability to perceive the actual passage of time remains unexplored. We investigate whether LLMs perceive the passage of time and adapt their decision-making accordingly through three complementary experiments. First, we introduce the Token-Time Hypothesis, positing that LLMs can map discrete token counts to continuous wall-clock time, and validate this through a dialogue duration judgment task. Second, we demonstrate that LLMs could use this awareness to adapt their response length while maintaining accuracy when users express urgency in question answering tasks. Finally, we develop BombRush, an interactive navigation challenge that examines how LLMs modify behavior under progressive time pressure in dynamic environments. Our findings indicate that LLMs possess certain awareness of time passage, enabling them to bridge discrete linguistic tokens and continuous physical time, though this capability varies with model size and reasoning abilities. This work establishes a theoretical foundation for enhancing temporal awareness in LLMs for time-sensitive applications.
SpeechDialogueFactory: A Framework for Natural Speech Dialogue Generation
Minghan Wang, Ye Bai, Yuxia Wang, Thuy-Trang Vu, Ehsan Shareghi, Gholamreza Haffari
Interspeech 2025
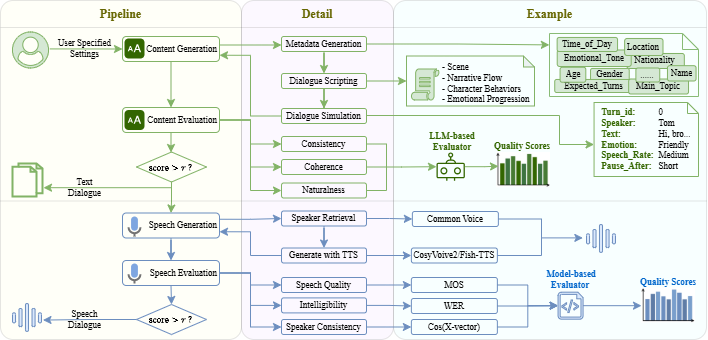
High-quality speech dialogue datasets are crucial for Speech-LLM development, yet existing acquisition methods face significant limitations. Human recordings incur high costs and privacy concerns, while synthetic approaches often lack conversational authenticity. To address these challenges, we introduce \textsc{SpeechDialogueFactory}, a production-ready framework for generating natural speech dialogues efficiently. Our solution employs a comprehensive pipeline including metadata generation, dialogue scripting, paralinguistic-enriched utterance simulation, and natural speech synthesis with voice cloning. Additionally, the system provides an interactive UI for detailed sample inspection and a high-throughput batch synthesis mode. Evaluations show that dialogues generated by our system achieve a quality comparable to human recordings while significantly reducing production costs. We release our work as an open-source toolkit, alongside example datasets available in English and Chinese, empowering researchers and developers in Speech-LLM research and development.
SpeechDialogueFactory: A Framework for Natural Speech Dialogue Generation
Minghan Wang, Ye Bai, Yuxia Wang, Thuy-Trang Vu, Ehsan Shareghi, Gholamreza Haffari
Interspeech 2025
High-quality speech dialogue datasets are crucial for Speech-LLM development, yet existing acquisition methods face significant limitations. Human recordings incur high costs and privacy concerns, while synthetic approaches often lack conversational authenticity. To address these challenges, we introduce \textsc{SpeechDialogueFactory}, a production-ready framework for generating natural speech dialogues efficiently. Our solution employs a comprehensive pipeline including metadata generation, dialogue scripting, paralinguistic-enriched utterance simulation, and natural speech synthesis with voice cloning. Additionally, the system provides an interactive UI for detailed sample inspection and a high-throughput batch synthesis mode. Evaluations show that dialogues generated by our system achieve a quality comparable to human recordings while significantly reducing production costs. We release our work as an open-source toolkit, alongside example datasets available in English and Chinese, empowering researchers and developers in Speech-LLM research and development.